Apache Kafka,作为一个分布式流处理平台,已成为业界的佼佼者。本文将深入探讨Kafka的内部结构、实现原理以及专业术语,帮助你更好地理解和使用这一强大的工具。
一、Kafka的内部结构
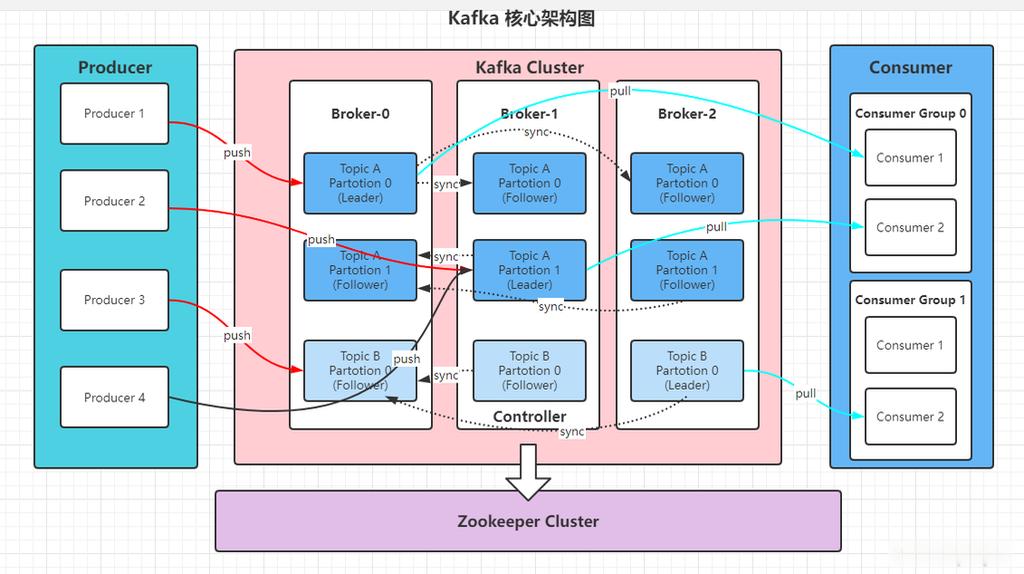
- Broker:Kafka集群中的服务器被称为Broker。它负责维护发布的数据。
- Topic:数据的分类单位,可以视为一个数据的订阅频道。
- Partition:为了实现数据的并行处理,每个Topic被分割成多个Partition。
- Producer:负责发布消息到Kafka Topic的客户端应用程序。
- Consumer:从Topic读取消息的客户端应用程序。
二、Kafka的特征
- 分布式系统:Kafka是一个分布式系统,可以跨多个服务器和数据中心扩展。
- 可伸缩性:Kafka通过Partition机制实现高效的数据处理和伸缩性。
- 容错性:每个Partition可以有多个副本,确保数据在节点故障时的可用性。
- 高性能:Kafka的设计允许它处理高吞吐量的数据,同时保持低延迟。
三、Kafka的专业名词
- Offset:在Partition中,每条消息都有一个特定的序号,称为Offset。
- Consumer Group:多个Consumer可以组成一个组,以共享数据处理任务。
- Replica:Partition的副本,保证数据安全和高可用。
四、如何使用Kafka组件
- 安装Kafka:首先在你的系统上安装Kafka。
- 启动Kafka服务:运行Kafka Broker和Zookeeper。
- 创建Topic:使用Kafka命令行工具创建Topic。
- 编写Producer和Consumer:根据需要编写代码,实现消息的发送和接收。
- 数据处理:运行你的应用程序,进行数据发布和订阅。
五、结语
Apache Kafka以其卓越的性能、可伸缩性和灵活性,在数据流处理领域占据重要地位。无论是简单的消息传递还是复杂的流处理,Kafka都能有效地支持你的业务需求。通过深入理解它的架构和原理,你将能更有效地利用这个强大的工具。